In Linux (Fedora with Gnome 42, and any other OS that uses “Document Scanner”), when you scan your documents, you can run an OCR (optical character recognition) process on the document to make the text searchable and copy-able.
You’ll need a couple of tools installed first, which is easy enough. Just run this:
sudo dnf install ocrmypdfAnd then run this:
sudo dnf install tesseract tesseract-langpack-eng tesseract-langpack-deuIf you’re on a Debian based OS then change dnf to apt.
Then, you’ll need a place where you store scripts for the system to run. Personally, I have a GIT folder for my Fedora tweaks, but any folder will do, as long as you know where it is and you don’t delete it.
Make a file called ocr-script.sh.
In that file, enter this script:
#!/bin/bash
if [[ "$3" == *".pdf" ]]; then
/usr/bin/ocrmypdf -l eng+deu --force-ocr "$3" "$3"
fiSave it and close it.
Then, make it executable by right-clicking it and selecting “Properties” and check the option called Executable as Program.

Go to your Document Scanner app and open Preferences.
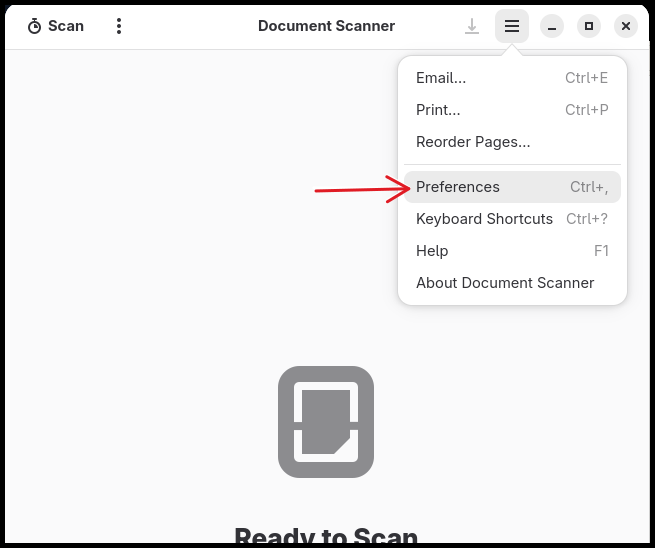
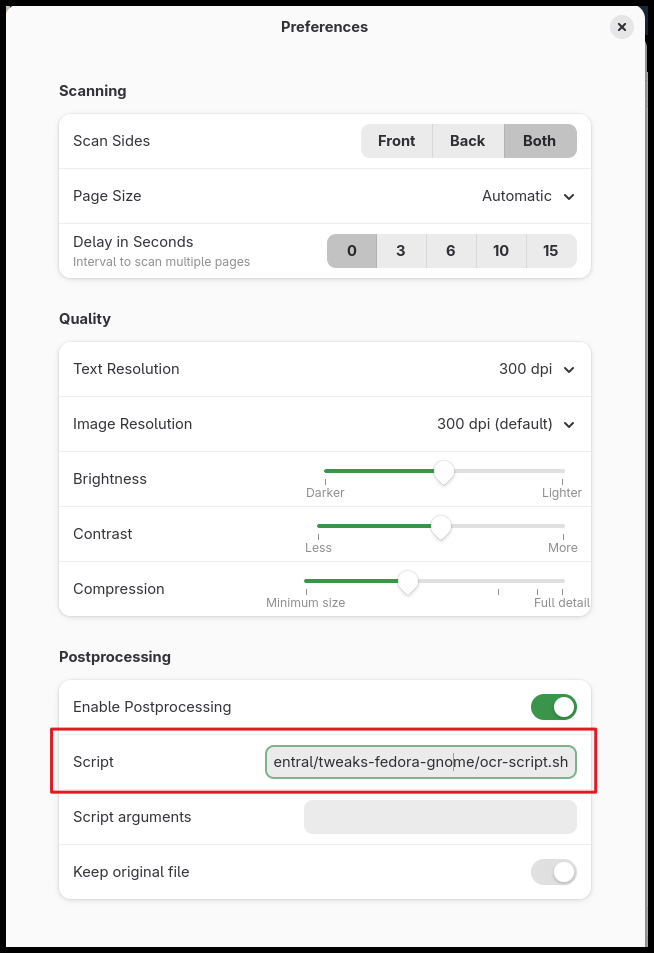
Check Enable Postprocessing.
In the Script field, enter the full path of your file (ocr-script.sh).
That should do it! Now, when you save a scanned document, it will run the OCR script on it and you’ll be able to select the text in the document, as well as find text using CTRL+F.